How neard works
This chapter describes how neard works with a focus on implementation details and practical scenarios. To get a better understanding of how the protocol works, please refer to nomicon. For a high-level code map of nearcore, please refer to this document.
High level overview
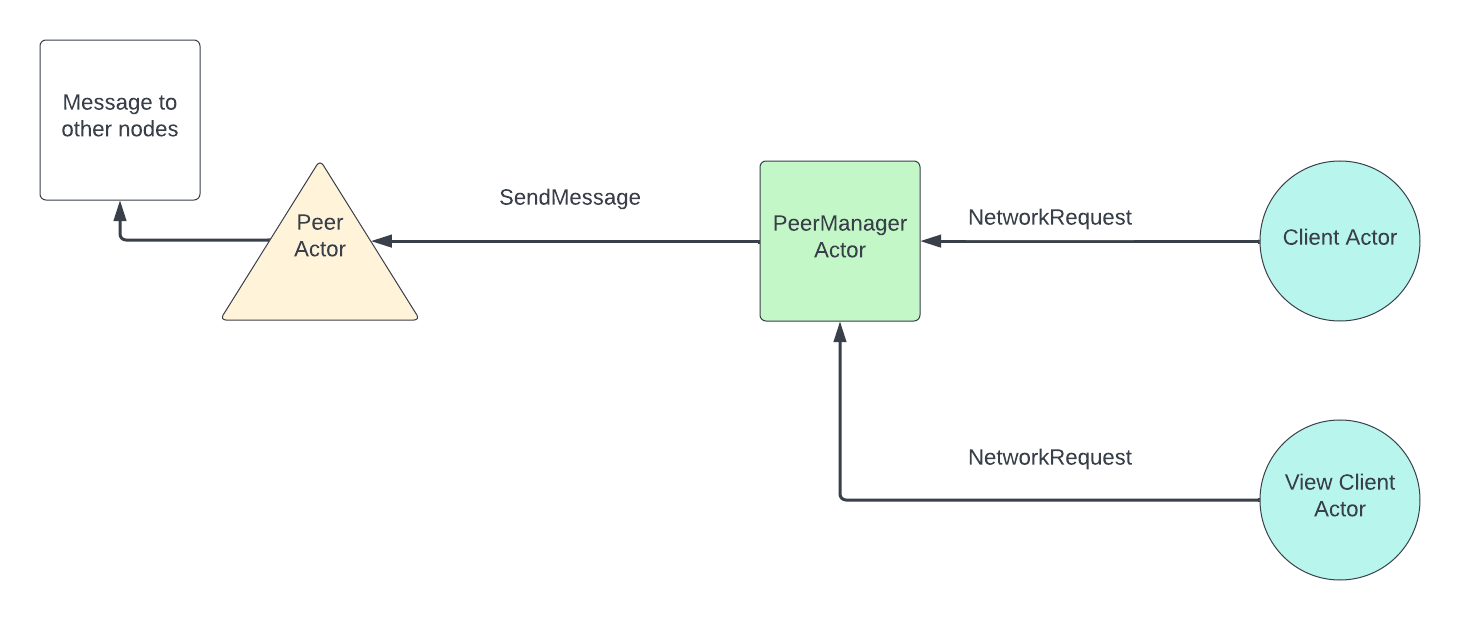
On the high level, neard is a daemon that periodically receives messages from the network and sends messages to peers based on different triggers. Neard is implemented using an actor framework provided by near-async.
There are several important actors in neard:
-
PeerActor- Each peer is represented by one peer actor and runs in a separate thread. It is responsible for sending messages to and receiving messages from a given peer. AfterPeerActorreceives a message, it will route it toClientActor,ViewClientActor, orPeerManagerActordepending on the type of the message. -
PeerManagerActor- Peer Manager is responsible for receiving messages to send to the network from eitherClientActororViewClientActorand routing them to the rightPeerActorto send the bytes over the wire. It is also responsible for handling some types of network messages received and routed throughPeerActor. For the purpose of this document, we only need to know thatPeerManagerActorhandlesRoutedMessages. Peer manager would decide whether theRoutedMessages should be routed toClientActororViewClientActor. -
ClientActor- Client actor is the “core” of neard. It contains all the main logic including consensus, block and chunk processing, state transition, garbage collection, etc. Client actor is single-threaded. -
ViewClientActor- View client actor can be thought of as a read-only interface to client. It only accesses data stored in a node’s storage and does not mutate any state. It is used for two purposes:- Answering RPC requests by fetching the relevant piece of data from storage.
- Handling some network requests that do not require any changes to the storage, such as header sync, state sync, and block sync requests.
ViewClientActorruns in four threads by default but this number is configurable.
Data flow within neard
Flow for incoming messages:

Flow for outgoing messages:
How neard operates when it is fully synced
When a node is fully synced, the main logic of the node operates in the following way (the node is assumed to track all shards, as most nodes on mainnet do today):
- A block is produced by some block producer and sent to the node through broadcasting.
- The node receives a block and tries to process it. If the node is synced it presumably has the previous block and the state before the current block to apply. It then checks whether it has all the chunks available. If the node is not a validator node, it won’t have any chunk parts and therefore won’t have the chunks available. If the node is a validator node, it may already have chunk parts through chunk parts forwarding from other nodes and therefore may have already reconstructed some chunks. Regardless, if the node doesn’t have all chunks for all shards, it will request them from peers by parts.
- The chunk requests are sent and the node waits for enough chunk parts to be
received to reconstruct the chunks. For each chunk, 1/3 of all the parts
(100) is sufficient to reconstruct a chunk. If new blocks arrive while waiting
for chunk parts, they will be put into an
OrphanPool, waiting to be processed. If a chunk part request is not responded to withinchunk_request_retry_period, which is set to 400ms by default, then a request for the same chunk part would be sent again. - After all chunks are reconstructed, the node processes the current block by applying transactions and receipts from the chunks. Afterwards, it will update the head according to the fork choice rule, which only looks at block height. In other words, if the newly processed block is of higher height than the current head of the node, the head is updated.
- The node checks whether any blocks in the
OrphanPoolare ready to be processed in a BFS order and processes all of them until none can be processed anymore. Note that a block is put into theOrphanPoolif and only if its previous block is not accepted. - Upon acceptance of a block, the node would check whether it needs to run garbage collection. If it needs to, it would garbage collect two blocks worth of data at a time. The logic of garbage collection is complicated and could be found here.
- If the node is a validator node, it would start a timer after the current
block is accepted. After
min_block_production_delaywhich is currently configured to be 1.3s on mainnet, it would send an approval to the block producer of the next block (current block height + 1).
The main logic is illustrated below:

How neard works when it is synchronizing
PeerManagerActor periodically sends a NetworkInfo message to ClientActor
to update it on the latest peer information, which includes the height of each
peer. Once ClientActor realizes that it is behind the highest height among
peers, it starts to sync.
The sync handler classifies the node into one of two categories based on how far behind it is:
-
Near horizon (within ~2-3 epochs of the tip). The node enters block sync directly. Header sync and block sync run together on every tick — header sync extends the chain of known headers while block sync follows it, requesting up to 10 blocks at a time. The node has recent enough state to apply blocks as they arrive, so no state sync is needed.
-
Far horizon (more than ~2-3 epochs behind). The node follows the full pipeline:
- Epoch sync: downloads a light-client proof that bootstraps the node to a recent epoch, skipping potentially millions of block headers.
- Header sync: downloads block headers from the epoch sync boundary forward, up to 512 headers at a time, until a valid state sync hash is found.
- State sync: downloads the full state snapshot at the sync hash (near the beginning of a recent epoch). For each tracked shard, state parts are downloaded from peers and assembled into the full state.
- Block sync: downloads and applies blocks from the sync point to the tip, with header sync running alongside.
If a non-genesis node needs epoch sync (it was running before but fell too far behind), the node writes a data reset marker, shuts down, and restarts fresh — wiping stale DB data before re-entering the far-horizon path.
For more details, see the sync documentation.
Note: when a block is received and its height is no more than 500 + the node’s current head height, the node requests its previous block automatically. This is called orphan sync and helps speed up the syncing process. If the height is more than 500 + the node’s current head height, the block is dropped.
How ClientActor works
ClientActor has some periodically running routines that are worth noting:
- Doomslug
timer -
This routine runs every
doomslug_step_period(set to 10ms by default) and updates consensus information. If the node is a validator node, it also sends approvals when necessary. - Block
production -
This routine runs every
block_production_tracking_delay(which is set to 10ms by default) and checks if the node should produce a block. - Log summary - Prints a log line that summarizes block rate, average gas used, the height of the node, etc. every 10 seconds.
- Resend chunk
requests -
This routine runs every
chunk_request_retry_period(which is set to 400ms). It resend the chunk part requests for those that are not yet responded to. - Sync -
This routine runs every
sync_step_period(which is set to 10ms by default) and checks whether the node needs to sync from its peers and, if needed, also starts the syncing process. - Catch
up -
This routine runs every
catchup_step_period(which is set to 100ms by default) and runs the catch up process. This only applies if a node validates shard A in epoch X and is going to validate a different shard B in epoch X+1. In this case, the node would start downloading the state for shard B at the beginning of epoch X. After the state downloading is complete, it would apply all blocks in the current epoch (epoch X) for shard B to ensure that the node has the state needed to validate shard B when epoch X+1 starts.